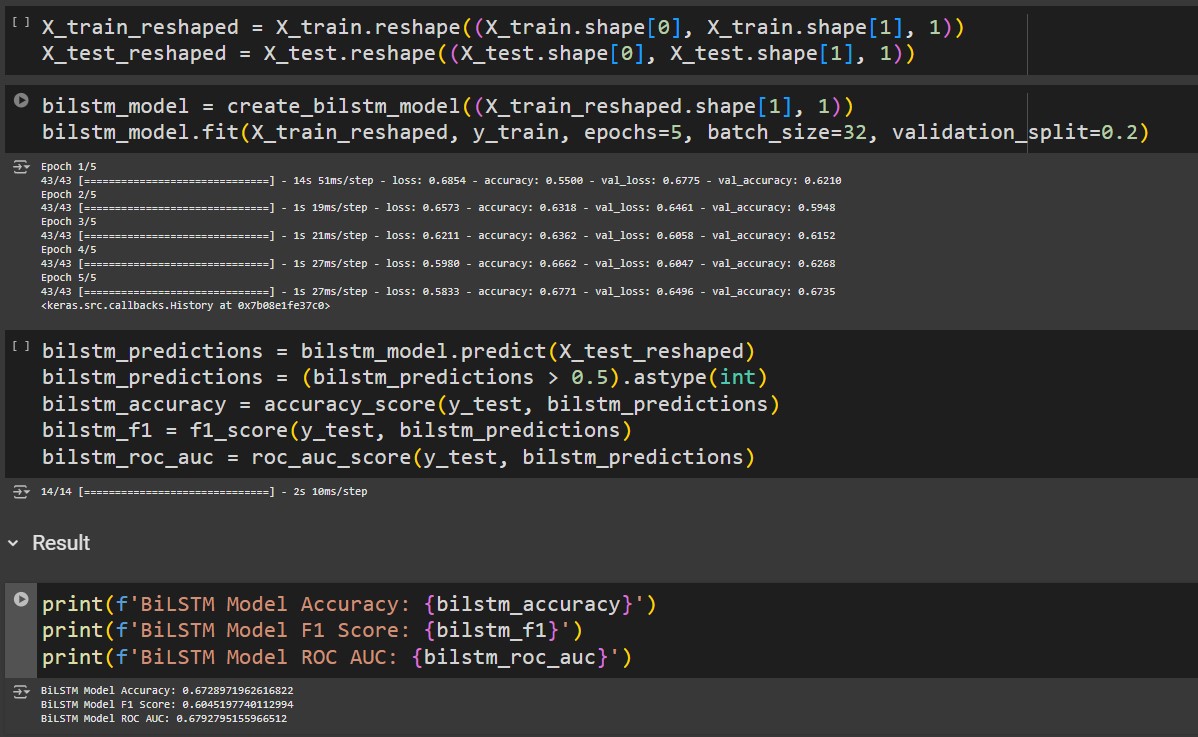
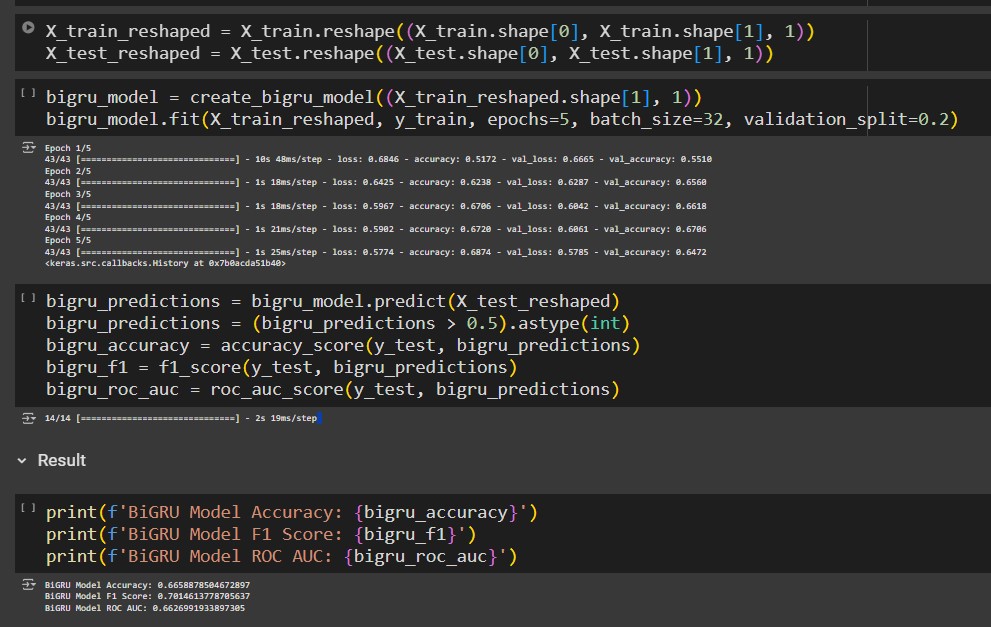

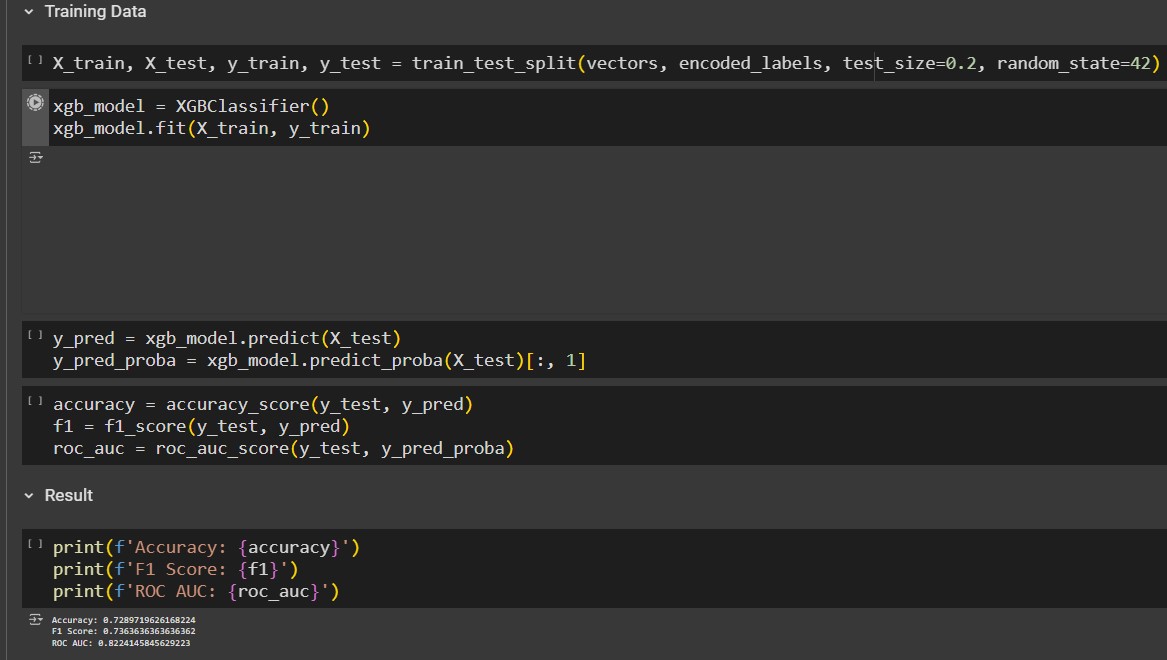
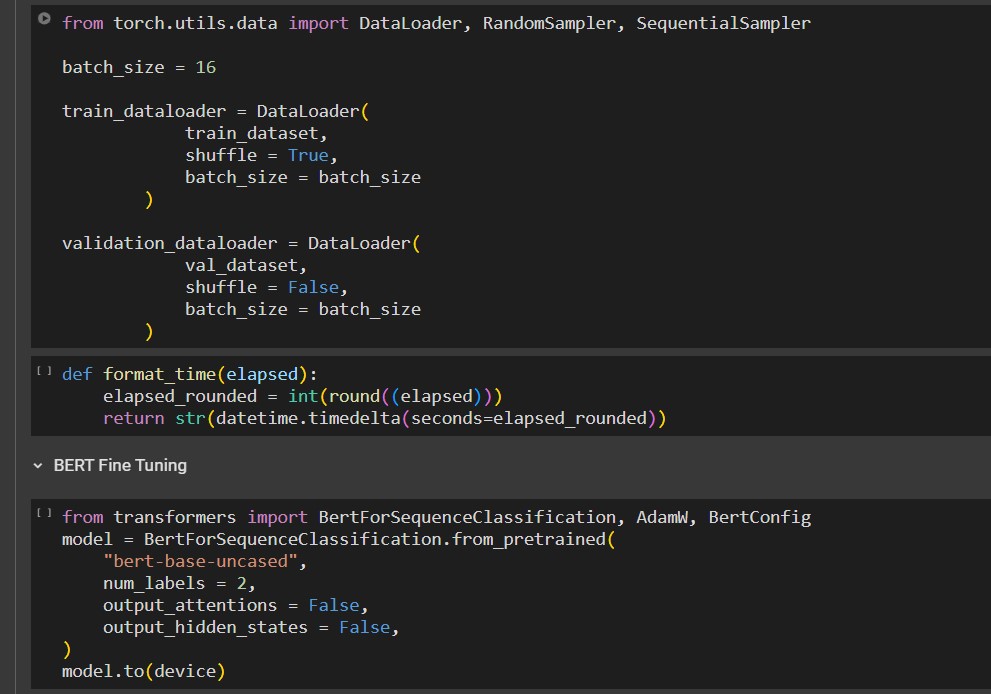
This research paper explores the comparative analysis of four machine learning models— BiLSTM, BiGRU, BERT, and XGBoost—to enhance the accuracy of hoax detection in text classification tasks. By leveraging deep learning techniques and gradient boosting algorithms, this study evaluates the performance, strengths, and limitations of each model. The findings aim to identify the most effective model for hoax detection, providing valuable insights into improving text-based classification systems. This research contributes to the growing field of automated hoax identification and aims to support efforts in combating misinformation.
We developed the result of the research paper using a combination of Python and Jupyter Notebook. The models were trained using the TensorFlow and Keras libraries, while the evaluation and analysis were conducted using the scikit-learn and pandas libraries.
I led my team in completing the research paper, taking full responsibility for overseeing each phase of the project. I managed the flow of the research, delegated tasks to my partner, and ensured that every stage followed the planned timeline. In addition, I was responsible for writing the research paper and do the model training and testing for BERT, ensuring that the documentation accurately reflected the work and findings of our study.